Linux kernel panic at down_read_trylock+9
最近一台主机突然内核崩溃, 系统通过 kdump 服务获取了崩溃时的 vmcore 文件. 我们在系统中安装相同内核版本对应的 kernel-debuginfo, kernel-debuginfo-common 包, 使用 crash 查看 vmcore 信息, 如下可以看到主机在 2019-07-15 05:52:53 开始崩溃, log 命令可以查看到崩溃的原因, 如下所示出现了空指针错误 BUG: unable to handle kernel NULL pointer dereference at 0000000000000008:
# crash /usr/lib/debug/lib/modules/3.10.0-862.14.4.el7.x86_64/vmlinux vmcore
crash 7.2.3-8.el7
......
KERNEL: /usr/lib/debug/lib/modules/3.10.0-862.14.4.el7.x86_64/vmlinux
DUMPFILE: vmcore [PARTIAL DUMP]
CPUS: 48
DATE: Mon Jul 15 05:52:53 2019
UPTIME: 232 days, 05:23:55
LOAD AVERAGE: 11.84, 7.15, 3.51
TASKS: 877
NODENAME: cz
RELEASE: 3.10.0-862.14.4.el7.x86_64
VERSION: #1 SMP Wed Sep 26 15:12:11 UTC 2018
MACHINE: x86_64 (2300 Mhz)
MEMORY: 127.7 GB
PANIC: "BUG: unable to handle kernel NULL pointer dereference at 0000000000000008"
PID: 269
COMMAND: "kswapd0"
TASK: ffff9c957bc3cf10 [THREAD_INFO: ffff9c857ba3c000]
CPU: 22
STATE: TASK_RUNNING (PANIC)
crash>
crash> log | tail -n 40
[20016417.175972] device eth0 entered promiscuous mode
[20016472.284421] BUG: unable to handle kernel NULL pointer dereference at 0000000000000008
[20016472.285758] IP: [<ffffffff9c0c2e89>] down_read_trylock+0x9/0x50
[20016472.287034] PGD 8000002039a98067 PUD 202cf00067 PMD 0
[20016472.288293] Oops: 0000 [#1] SMP
crash>
crash> bt
PID: 269 TASK: ffff9c957bc3cf10 CPU: 22 COMMAND: "kswapd0"
#0 [ffff9c857ba3f718] machine_kexec at ffffffff9c062a0a
#1 [ffff9c857ba3f778] __crash_kexec at ffffffff9c1166c2
#2 [ffff9c857ba3f848] crash_kexec at ffffffff9c1167b0
#3 [ffff9c857ba3f860] oops_end at ffffffff9c71d728
#4 [ffff9c857ba3f888] no_context at ffffffff9c70c84d
#5 [ffff9c857ba3f8d8] __bad_area_nosemaphore at ffffffff9c70c8e4
#6 [ffff9c857ba3f928] bad_area_nosemaphore at ffffffff9c70ca55
#7 [ffff9c857ba3f938] __do_page_fault at ffffffff9c7206e0
#8 [ffff9c857ba3f9a0] do_page_fault at ffffffff9c7208d5
#9 [ffff9c857ba3f9d0] page_fault at ffffffff9c71c758
[exception RIP: down_read_trylock+9]
RIP: ffffffff9c0c2e89 RSP: ffff9c857ba3fa80 RFLAGS: 00010202
RAX: 0000000000000000 RBX: ffff9c956f7b4230 RCX: 0000000000000000
RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000008
RBP: ffff9c857ba3fa80 R8: ffffe7f22a9b0020 R9: 000000103578f000
R10: 0000000000000000 R11: 000000000000003c R12: ffff9c956f7b4231
R13: ffffe7f22a9b0000 R14: 0000000000000008 R15: ffffe7f22a9b0000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#10 [ffff9c857ba3fa88] page_lock_anon_vma_read at ffffffff9c1d72a5
#11 [ffff9c857ba3fab8] page_referenced at ffffffff9c1d754a
#12 [ffff9c857ba3fb38] shrink_active_list at ffffffff9c1ac0e4
#13 [ffff9c857ba3fbf0] shrink_lruvec at ffffffff9c1ac651
#14 [ffff9c857ba3fcf0] shrink_zone at ffffffff9c1aca06
#15 [ffff9c857ba3fd48] balance_pgdat at ffffffff9c1adcfc
#16 [ffff9c857ba3fe20] kswapd at ffffffff9c1adfc3
#17 [ffff9c857ba3fec8] kthread at ffffffff9c0bdf21
#18 [ffff9c857ba3ff50] ret_from_fork_nospec_begin at ffffffff9c7255dd
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 32871402 125.4 GB ----
FREE 92978 363.2 MB 0% of TOTAL MEM
USED 32778424 125 GB 99% of TOTAL MEM
SHARED 4986392 19 GB 15% of TOTAL MEM
BUFFERS 0 0 0% of TOTAL MEM
CACHED 6046066 23.1 GB 18% of TOTAL MEM
SLAB 242491 947.2 MB 0% of TOTAL MEM
TOTAL HUGE 0 0 ----
HUGE FREE 0 0 0% of TOTAL HUGE
TOTAL SWAP 16773867 64 GB ----
SWAP USED 12493 48.8 MB 0% of TOTAL SWAP
SWAP FREE 16761374 63.9 GB 99% of TOTAL SWAP
COMMIT LIMIT 33209568 126.7 GB ----
COMMITTED 27373280 104.4 GB 82% of TOTAL LIMIT
上述的 bt 显示了崩溃时的堆栈信息, 即系统在处理 down_read_trylock+9 时崩溃, kmem 则显示了崩溃时的内存使用信息, 可以看到当时可用的内存仅为 363.2MB, 不过从整个堆栈的信息来看, kswapd0 进程通过 balance_pgdat 开始均衡各自 CPU 节点(node0, 对应上述的 CPU: 22)对应的内存, 进而开始进行内存的回收操作(shrink_zone, shrink_active_list函数), 后续内核开始检测匿名页(page_referenced -> page_referenced_anon -> page_lock_anon_vma_read), 最后在 down_read_trylock 函数中崩溃. 如下所示, 内存的消耗速度很快:
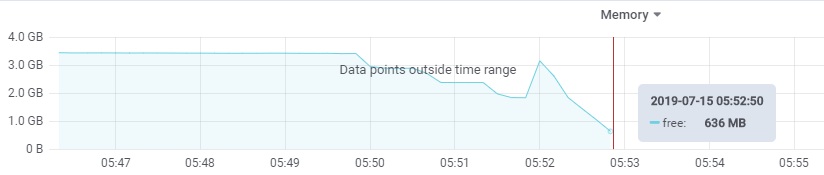
参考红帽文档 redhat-277985, 可以获取到以下信息:
crash> dis -rl down_read_trylock+9
/usr/src/debug/kernel-3.10.0-862.14.4.el7/linux-3.10.0-862.14.4.el7.x86_64/kernel/rwsem.c: 34
0xffffffff9c0c2e80 <down_read_trylock>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff9c0c2e85 <down_read_trylock+5>: push %rbp
0xffffffff9c0c2e86 <down_read_trylock+6>: mov %rsp,%rbp
/usr/src/debug/kernel-3.10.0-862.14.4.el7/linux-3.10.0-862.14.4.el7.x86_64/arch/x86/include/asm/rwsem.h: 83
0xffffffff9c0c2e89 <down_read_trylock+9>: mov (%rdi),%rax
crash> dis -rl ffffffff9c1d72a5
/usr/src/debug/kernel-3.10.0-862.14.4.el7/linux-3.10.0-862.14.4.el7.x86_64/mm/rmap.c: 501
0xffffffff9c1d7250 <page_lock_anon_vma_read>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
...
crash> page.mapping ffffe7f22a9b0000
mapping = 0xffff9c956f7b4231
crash> kmem ffffe7f22a9b0000
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffe7f22a9b0000 aa6c00000 ffff9c956f7b4231 7fe793e00 2 2fffff00084048 uptodate,active,head,swapbacked
crash> struct page {
flags = 13510794587684936,
mapping = 0xffff9c956f7b4231,
{
{
index = 34334129664,
....
crash> struct page.mapping ffff9c956f7b4231
mapping = 0x0 # 空指针
crash> kmem 0xffff9c956f7b4231
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffe7f280bded00 202f7b4000 0 0 1 6fffff00000000
crash> kmem 0000000000000008
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffe7f200000000 0 0 0 0 400 reserved
R13 的地址即为 page_lock_anon_vma_read 函数中的 page 指针地址, 不过使用 kmem 来看, page.mapping(ffff9c956f7b4231) 为 NULL 指针, RDI(目标地址寄存器) 0000000000000008 同样为 NULL 指针, 为保留的区域. 后续的程序指令寄存器(RIP: down_read_trylock+9) 访问了空指针进而引起崩溃, 地址对应的内核代码大致如下所示:
# /source/kernel/rwsem.c
30 /*
31 * trylock for reading -- returns 1 if successful, 0 if contention
32 */
33 int down_read_trylock(struct rw_semaphore *sem)
34 {
35 int ret = __down_read_trylock(sem);
36
37 if (ret == 1) {
38 rwsem_acquire_read(&sem->dep_map, 0, 1, _RET_IP_);
39 rwsem_set_reader_owned(sem);
40 }
41 return ret;
42 }
// /source/mm/rmap.c
/*
* Similar to page_get_anon_vma() except it locks the anon_vma.
*
* Its a little more complex as it tries to keep the fast path to a single
* atomic op -- the trylock. If we fail the trylock, we fall back to getting a
* reference like with page_get_anon_vma() and then block on the mutex.
*/
struct anon_vma *page_lock_anon_vma_read(struct page *page)
{
struct anon_vma *anon_vma = NULL;
struct anon_vma *root_anon_vma;
unsigned long anon_mapping;
rcu_read_lock();
anon_mapping = (unsigned long) ACCESS_ONCE(page->mapping);
if ((anon_mapping & PAGE_MAPPING_FLAGS) != PAGE_MAPPING_ANON)
goto out;
if (!page_mapped(page))
goto out;
anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
root_anon_vma = ACCESS_ONCE(anon_vma->root);
if (down_read_trylock(&root_anon_vma->rwsem)) { // <---- 在此崩溃
/*
* If the page is still mapped, then this anon_vma is stil
参考
bugzilla-1305620
redhat-2779851
避免出现此类问题的措施
从红帽的知识库中来看, 这个问题并没有完全解决, 最新的 7.5 版本依旧存在此问题, 不过红帽也提供了几种缓解的方式:
Root Cause
The regression was introduced when the code was refactored to reduce the amount of locking
in page table access and reads.
When checking if a page table pointed to THP pages or not, a small window of opportunity
existed for the mapping to be referenced after it was already deallocated.
上述提到可能的原因是由于需要减少访问和读取锁定的页表时可能会引起此类问题, 另外禁用 THP(Transparent HugePages) 则可能减少此类问题出现的概率. 另外我们从 vmcore 的信息来看, 可能是内存不足而触发了此类 bug, 所以主要通过以下方式降低发生错误的概率:
加大主机的可用内存
可以适当减少程序的内存占用, 避免程序过度使用内存. 如果条件允许可以给主机增加更多的内存. 另外也可以通过 sys-unmap-file 工具来释放系统中不怎么使用的缓存空间.
调整系统内存的回收策略
参见 page allocation failure, 主要调整以下参数:
增加 vm.min_free_kbytes 的参数值, 调低 vm.lowmem_reserve_ratio 的参数值;
这种方式只能缓解 kernel 报提示消息的频率, 加大 vm.min_free_kbytes 的值意味着加大了水位值(low, high), kswapd 进程可以提前做 reclaim 和释放内存的操作, 但是在突然需要大内存操作的时候还是会出现这个错误. 主机的报错如果频繁的话可以考虑调高该参数(Centos 7 的默认值 90112(88M)) 另外调高 vm.lowmem_reserve_ratio 参数值即意味着 NORMAL 内存不足的时候内核可以借用 DMA32/DMA 的内存来救急, 但是也不能设置过高, 调低该值意味着预留更多的保留页, 避免低端内存使用不足. 如下所示调低 lowmem_reserve_ratio[1]`(对应 DMA32 区域) 的值, 可以避免低端内存不足而引起的内存分配失败的问题:
256 128 32