如何审计 Linux 系统的操作行为
很多时候我们为了安全审计或者故障跟踪排错, 可能会记录分析主机系统的操作行为. 比如在系统中新增了一个用户, 修改了一个文件名, 或者执行了一些命令等等, 理论上记录的越详细, 越有利于审计和排错的目的. 不过过剩的记录也会为分析带来不少麻烦, 尤其是将很多主机的记录行为发送到固定的远程主机中, 数据越多, 分析的成本便越大.
实际上, 绝大多数的系统行为都是重复多余的, 比如 cron 任务计划, 我们信任的程序等, 这些都会产生大量的记录, 但很少用于审计分析. 基于这个需求, 我们在审计系统操作行为的时候, 至少应该添加一些过滤规则, 避免记录过多的无用信息, 比如重复的 cron 任务操作, 同时也要避免记录一些敏感信息, 比如带密码的命令行操作. 满足这些需求后, 我们在审计系统操作行为的时候应该遵照以下准则:
1. 忽略 cron, daemon 产生的记录;
2. 忽略带密码的敏感命令行或脚本操作记录;
3. 忽略监控用户(比如 nagios, zabbix, promethus 等) 产生的记录;
4. 忽略频繁产生日志的操作行为;
第二点为可选项, 在以明文方式传输到远程日志服务器的时候, 我们建议忽略记录. 第四点则需要着重强调, 比如我们记录一台 web 主机中的所有 connect, accept 网络系统调用操作, 虽然可以据此分析该主机所有的网络访问请求, 达到安全或者故障定位的目的, 但是这两个系统调用可能在短时间内产生大量的日志, 对 kernel 和网络日志传输都会产生不小的压力, 这种大海捞针似的审计方式我们不推荐直接在线上主机中使用, 建议仅在需要定位问题的时候启用.
下面我们主要介绍有哪几种方式可以实现系统操作的审计:
history 记录方式
history 方式 很传统也很简单, 本质上是将历史的命令发送到 syslog 日志中, 可以用来简单记录用户的命令操作历史. 但是这种方式有几个重要的缺点, 并不适合审计的目的:
1. 容易被修改, 被绕过;
2. 记录太简单, 没有上下文信息(比如 pid, uid, sid 等);
3. 无法记录 shell 脚本内的操作;
4. 无法记录非登录的操作;
5. 难以实现过滤规则;
定制 bash 记录方式
定制 bash 方式 比较冷门, 本质上是为 bash 源程序增加审计日志的功能, 开发者可以据此添加一些操作命令的上下文信息, 不过很难记录子进程的信息, 其缺点和上述的 history 方式类似:
1. 容易被绕过, 用户可以使用 csh, zsh 等;
2. 无法记录 shell 脚本内的操作;
3. 过滤规则可能单一;
4. 可能需要不停的更新 bash 版本, 工作量大, 否则容易被发行版替换;
snoopy 记录方式
snoopy 方式 相对新颖, 本质上是封装了 execv, execve 系统调用, 以系统预加载(preload)的方式实现记录所有的命令操作. 如下调用关系:
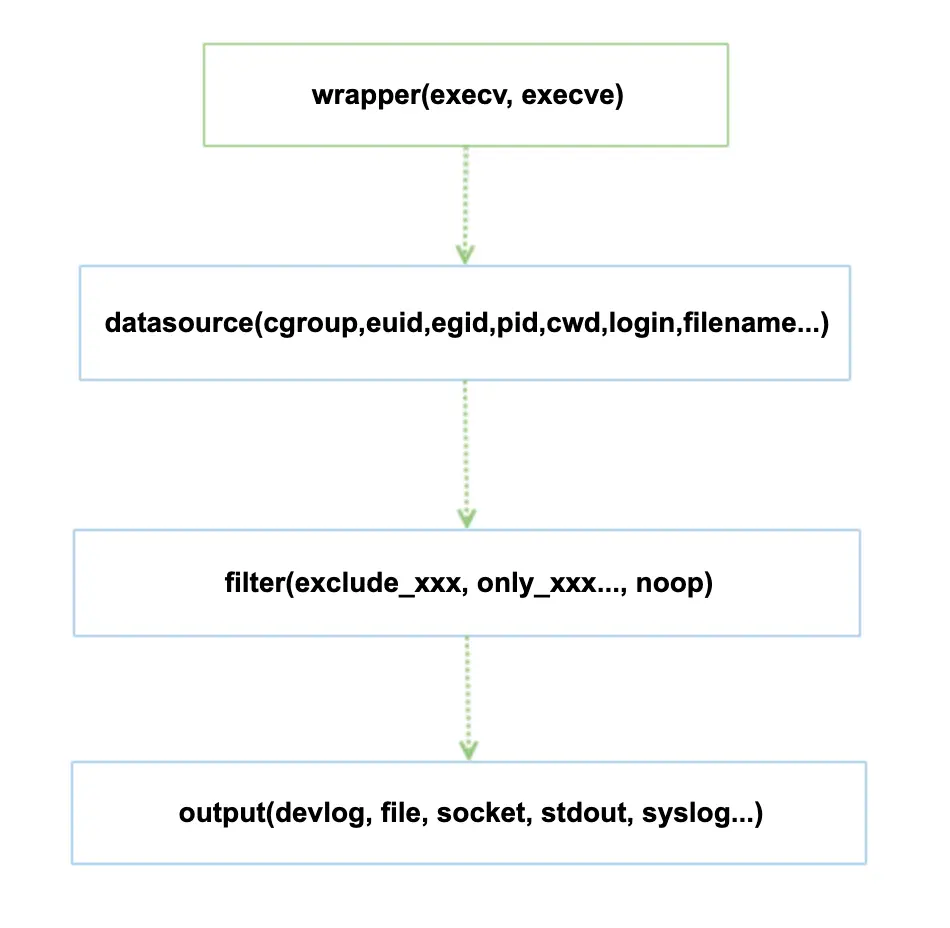
更多介绍可以参考以前的文章 snoopy 如何记录系统执行过的命令. 目前大部分系统执行命令时都通过 execv, execve 系统调用执行, 这点就和会话无关, 几乎所有的情况下, 只要通过这两个系统调用执行命令, 就会将操作行为记录下来, 从目前的最新版本(2.4.8)来看, snoopy 有几个优点:
1. 难以绕过, 只要设置了 PRELOAD, 就肯定会记录;
2. 无论是否存在 tty 会话, 都会记录 execv, execve 相关的命令行操作, 包含详细的进程上下文信息;
3. 可以记录 shell 脚本内部的操作行为, 脚本内的命令行操作大部分都会调用 execv, execve;
4. 可以记录操作行为的参数, 比如指定了用户名, 密码等;
5. 过滤规则丰富, 可以忽略指定 daemon, uid, 也可以仅记录指定的 uid;
如下日志示例:
Oct 27 11:34:31 cz-t1 snoopy[24814]: [time_ms:778 login:cz uid:0 pid:24814 ppid:24676 sid:24579 tty:/dev/pts/0 cwd:/root filename:/bin/uptime username:root]: uptime -p
上述日志显示 root 用户执行了 uptime 命令, 参数包含 -p, 对应的进程上下文信息都比较全, 不过 snoopy 的缺点也比较明显, 主要包含以下几点:
1. 仅支持 execv, execve 相关系统调用的操作;
2. 不设置规则可能产生的日志过多, 对日志搜集系统造成很大的负担;
3. 暂不支持过滤敏感信息规则;
在实际的使用中, snoopy 记录方式可以很详细的记录所有的命令操作信息, 帮助我们定位很多疑难问题. 不过我们也需要通过过滤规则来避免产生过多的信息, snoopy 的过滤规则可以满足以下需求:
1. 忽略 cron, daemon 产生的记录;
2. 忽略监控用户(比如 nagios, zabbix, promethus 等) 产生的记录;
比如以下配置, 即可忽略 crond, my-daemon 守护进程, 忽略 zabbix 用户:
# zabbix uid 为 992
filter_chain = exclude_uid:992;exclude_spawns_of:crond,my-daemon
备注: 过滤规则在 (filtering.c - snoopy_filtering_check_chain) 函数实现, 由 log.c - snoopy_log_syscall_exec 函数调用, 过滤规则为事后行为, 即在打印日志的时候判断是否满足过滤规则, 并非事前行为.
另外, 我们在 snoopy 的基础上增加了 exclude_comm 过滤规则, 我们可以忽略记录指定的命令, 比如以下:
filter_chain = exclude_uid:992;exclude_comm:mysql,mongo,redis-cli
exclude_comm 指定忽略以 mysql, mongo 和 redis-cli 工具执行的命令, 很多管理员或者脚本在使用这些工具的时候常常会加上用户密码信息, 这在明文环境中是很危险的行为, exclude_comm 规则简单的避免了常用工具泄漏敏感信息的隐患.
sysdig 记录方式
大部分情况下, 我们可以通过 strace 工具来简单的追踪进程的行为, 比如 MySQL 为什么不能启动, php 为什么返回异常等等. 不过 strace 程序是基于 ptrace 系统调用实现的, ptrace 为了能够获取到其他系统调用的详细信息, 需要做很多复杂的操作, 如果进程很繁忙, strace 就会对程序产生很大的影响. 这也是我们不建议对线上程序, 尤其是正在运行的游戏服, DB 等进程使用 strace 的原因.
sysdig 工具则以另一种创新的方式获取所有的系统调用, 可以很好的弥补 strace 的不足, 从下图来看:
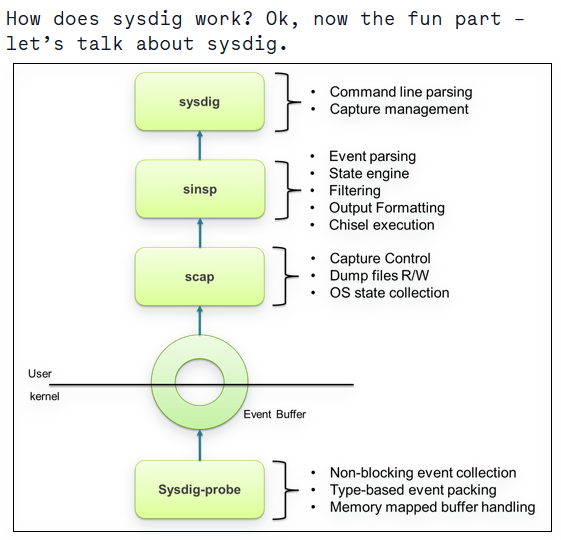
sysdig 以内核模块的方式监控获取所有的系统调用, 其使用方式类似 libpcap/tcpdump 的用法, 可以将一段时间内系统调用的数据暂存起来供以后的跟踪分析. 因为对于 系统调用 而言, 用户态层面的操作最终都会陷入到内核态, 由内核去完成对应的功能. 所以 sysdig 在内核态也就能很方便的获取到进程的上下文信息. 另外 sysdig 以非阻塞(non-blocking), 零拷贝(zero-copy) 的方式获取数据, 所以在实际使用中对在线的业务只有很轻微的影响. 我们线上繁忙程序的分析通常可以使用 sysdig 来跟踪排错.
比如以下实例, 我们可以跟踪网络相关的调用找出哪个程序访问了另一台主机的端口(通常我们很难追踪到定期任务类程序的网络连接行为, 比如检测一个端口存活的工具, 连接操作是很快速的行为, 人工很难发现):
# sysdig fd.port=11211
111107 21:57:30.101635885 2 telegraf (24077) < connect res=-115(EINPROGRESS) tuple=10.1.0.25:34700->10.1.0.25:11211
111125 21:57:30.101704276 3 memcached (19673) < accept fd=30(<4t>10.1.0.25:34700->10.1.0.25:11211) tuple=10.1.0.25:34700->10.1.0.25:11211 queuepct=0 queuelen=0 queuemax=128
111126 21:57:30.101707830 3 memcached (19673) > fcntl fd=30(<4t>10.1.0.25:34700->10.1.0.25:11211) cmd=4(F_GETFL)
可以很方便的看到是 telegraf 监控程序访问了 11211 端口, 实际使用中, 我们更多的是暂存抓到的数据, 传到其他主机中查看, 如下所示:
# sysdig fd.port=11211 -w 11211.sysdig
# sysdig -r 11211.sysdig
2799 22:00:04.397791648 1 memcached (19676) < sendmsg res=1046 data=STAT pid 19673..STAT uptime 1990036..STAT time 1621692003..STAT version 1.4.15..
2800 22:00:04.397806812 1 telegraf (24072) > read fd=9 size=4096
2801 22:00:04.397810766 1 telegraf (24072) < read res=1046 data=STAT pid 19673..STAT uptime 1990036..STAT time 1621692003..STAT version 1.4.15..
更多 sysdig 示例可以参考: Sysdig-Examples
auditd 记录方式
auditd 记录方式 本身存在内核层面(kauditd 进程)的支持, 它实现了一个大而全的框架, 几乎能监控所有想监控的指标, 不管是按照访问模式, 系统调用还是事件类型触发, 都能满足监控需求. 因为其提供了内核层面的支持, 所以本质上比起 snoopy(仅封装 execv, execve 系统调用)要更加强大和健全.
生成的日志也容易查看, 进程的上下文信息, 参数信息都很全面, 如下所示:
type=SYSCALL msg=audit(1603800704.305:5304075): arch=c000003e syscall=59 success=yes exit=0 a0=1c79fd0 a1=1bf51a0 a2=1bd4450 a3=7ffe7270d320 items=2 ppid=95264 pid=99702 auid=0 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=571973 comm="mysql" exe="/usr/bin/mysq
l" key="command"
type=EXECVE msg=audit(1603800704.305:5304075): argc=5 a0="/usr/bin/mysql" a1="-h" a2="127.0.0.1" a3="-P" a4="3301"
更多说明见: understanding-audit-log
auditd 整体上为分离的架构, auditctl 可以控制 kauditd 生成记录的策略, kauditd 生成的记录事件会发送到 auditd 守护程序, audisp 可以消费 auditd 的记录到其它地方. 其主要的几个工具包含如下:
| name | description |
|---|---|
| auditd | audit 守护程序, audit 相关配置的加载, 日志落盘等都通过 auditd 完成 |
| auditctl | 用来控制 kernel audit 相关的规则, 可以及时生效, 过滤通常使用 auditctl 实时修改 |
| audisp | 和 auditd 守护程序通信, 将收到的记录信息发送到别处, 比如发到 syslog 中 |
| augenrules, ausearch, autrace, aureport | audit 提供的一些辅助分析的工具 |
auditd 的策略规则主要根据 -a 或 -w 参数设置, 可以将策略规则保存到默认的 /etc/audit/rules.d/audit.rules 配置, 也可以通过 auditctl 动态的调整. 值得注意的是策略规则的加载是按照顺序生效的, 我们在配置例外情况的时候就需要注意将例外情况添加到合适的位置, 比如参考 auditd-best-practice 中给出的示例, 如果需要忽略 mysql, mongo 等命令工具, 就需要将以下策略加到合适的位置(-a always,exit 规则之前):
### ignore common tools
-a never,exit -F arch=b64 -F exe=/usr/bin/redis-cli
-a never,exit -F arch=b64 -F exe=/usr/bin/mysql
-a never,exit -F arch=b64 -F exe=/usr/bin/mongo
....
## Kernel module loading and unloading
-a always,exit -F perm=x -F auid!=-1 -F path=/sbin/insmod -k modules
....
never和always所能支持的-F过滤字段不尽相同, 如果要按照 exe 忽略指定的工具路径, 只能通过never实现, exe 为执行工具的路径, 需要设置其绝对值, 这点没有 snoopy 的 exclude_comm 方便.
更多规则设置见: audit-define
在实际的使用中, 我们不建议对常见的一些系统调用进行监控, 比如connect, accept, execve 等都是日志高产的行为, 应该在需要定位问题的时候开启. 当然如果过滤策略设置的足够详细, 比如忽略了指定用户, crond 进程等, 就可以比较放心的监控这些系统调用.
一些安全工具(比如 go-audit, hids)实现了与 kauditd 内核进程通信, 可以接收 audit 相关的日志, 这种方式替换了 auditd 服务, 灵活性很强, 可以做很多定制功能需求, 不过基本使用上还是建议避免收集过多的数据.
最后, 我们可以参考 slack 的官方文章, 了解更多 audit 相关的实践经验:
syscall-auditing-at-scale
distributed-security-altering
eBPF 记录方式
eBPF 在较新版本的 Linux 内核中实现, 提供了动态追踪的机制, 可以阅读之前的文章 Linux 系统动态追踪技术介绍 了解更多动态追踪相关的知识. bpftrace 和 bcc 是基于 eBPF 机制实现的工具, 方便大家对系统的调试和排错, bcc 提供了很多工具集, 从应用到内核, 不同层面的工具应有尽有, 比如 execsnoop 即可记录系统中所有的 execv, execve 相关的命令执行:
# ./execsnoop
PCOMM PID PPID RET ARGS
bash 32647 32302 0 /bin/bash
id 32649 32648 0 /usr/bin/id -un
hostname 32651 32650 0 /usr/bin/hostname
uptime 410 32744 0 /bin/uptime
其它更细致的记录可以参考 bcc 工具说明. 值得注意的是, eBPF 仅适用于 Linux 4.1+ 的版本, 以 eBPF 开发的进度的来看, eBPF 在 kernel-4.10 之后的支持才相对全面, 线上在使用的时候尽量选择较高内核版本的发行版(比如 Centos 8, Debian 10 等). 另外 Readhat/Centos 7 从 7.6 (3.10.0-940.el7.x86_64) 版本开始支持 eBPF 特性, 不过内核版本较低, 并没有支持所有的特性, 其主要目的在于试用此技术:
总结
从上述介绍可以看到, 跟踪系统的操作行为其实就是为了更方便的追溯和排查问题. 在实际的使用中, 我们建议通过 snoopy 或 auditd 来实现系统操作的跟踪, 如果系统内核较高, 一些细致的记录追踪可以通过 eBPF 方式实现. 当然我们可以记录的信息发送到 ELK 等日志平台做一些策略方面的告警. 不过在具体的实践中, 我们需要做好细致的过滤规则避免产生大量重复且收效甚微的数据.