运维同学需要掌握的 MySQL 数据库知识
很多公司的运维同学或许都身兼数职, 其中打交道最多的应该要数操作系统和数据库, 从大的层面来看, 我们需要对系统和数据库都有一定的了解才能让服务稳定的运行. 不过要熟悉数据库一般都需要大量的实践才能对其有一定程度的理解, 这样才能避免很多故障产生. 下面则简单介绍运维同学需要掌握的 MySQL 数据库知识, 以便大家对 MySQL 的操作有个整体的认识:
MySQL 方面知识
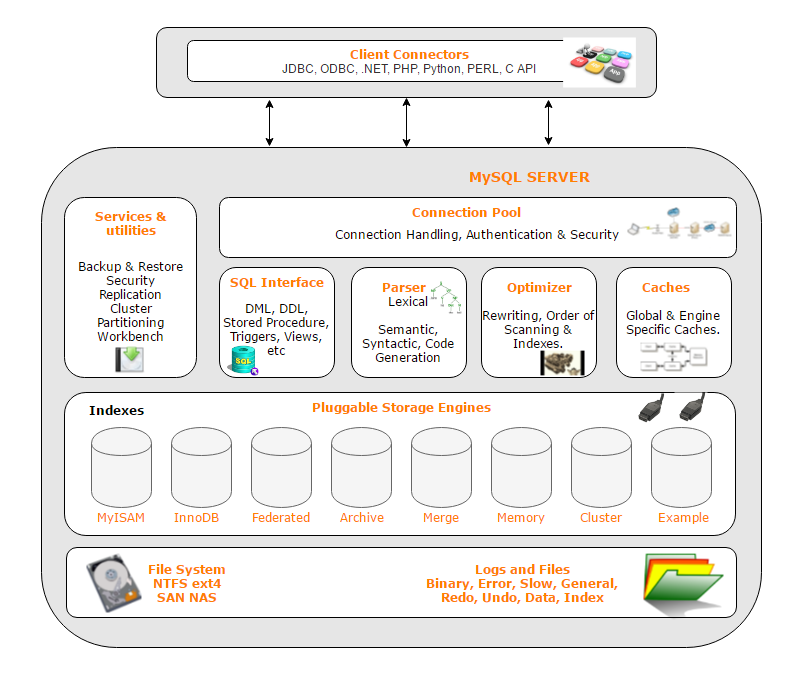
了解 MySQL 的架构设计
不同版本的 MySQL 大致都包含以下几个大的模块:
连接层
服务管理层
SQL 解析, 优化器, 缓存;
插件式存储引擎
文件系统存储
大致的架构图如下所示:
更多见:
understanding-mysql-architecture
了解常见的数据类型及不同数据类型占用的字节大小
熟悉不同的数据类型, 方便我们估算表行数与数据大小的关系, 可以对不同类型的表字段产生更强的敏感度.
更多见: mysql-data-type
了解常见的索引及索引适用场景
需要熟悉以下不同索引的适用条件:
1. 联合索引;
2. 前缀索引;
3. 覆盖索引;
4. 唯一索引;
5. 主键及第二索引的区别;
更多见: mysql-index
熟悉 MySQL 的权限结构
MySQL 通过 user 和 host 来唯一标识一个用户, 高版本也有 role 角色的存在. 运维同学在创建用户的时候尽量保持最小原则, 仅分配程序需要的权限即可.
更多见:
熟悉 MyISAM 和 InnoDB 的不同
sql 在不同的引擎上执行的时候可能会加不同粒度的锁, InnoDB 支持事务, 需要了解四种隔离级别对程序的影响.
更多见:
熟悉主从复制
对主从复制需要了解以下信息:
1. 基于 binlog 格式(statement, row 或 mixed)实现复制;
2. binary log 和 relay log 的区别;
3. 高版本(5.6 及以上) GTID 的原理;
4. 常见 slave 错误的修复方法;
熟悉常见的 MySQL 维护操作
不同版本数据库的 DDL 操作存在不同的行为, 在改表的时候要注意可能会引起的加锁操作. 如果想忽略版本的影响统一进行处理, 可以参考 percona 的以下工具:
pt-query-digest # 主要用来排错
pt-online-schema-change # 在线修改表结构
更多见:
innodb-online-ddl
percona-toolkit
常见参数调整
可参考设置:
[mysql]
prompt = 'mysql \u@[\h:\p \d] > '
default-character-set = utf8
[mysqladmin]
default-character-set = utf8
[mysqlcheck]
default-character-set = utf8
[mysqldump]
default-character-set = utf8
[mysqlimport]
default-character-set = utf8
[mysqlshow]
default-character-set = utf8
[client]
port = 3396
socket = /export/mysql/node3306/data/s3306
[mysqld]
# common InnoDB/XtraDB settings
innodb_buffer_pool_size = 32G # x 1.2 + 2GB for OS = 32GB node w/o MyISAM
innodb_data_file_path = ibdata1:200M:autoextend
innodb_log_file_size = 512M # suitable for most environments
innodb_log_files_in_group = 4
innodb_log_buffer_size = 32M # no bigger than max_allowed_packet
innodb_flush_log_at_trx_commit = 2
innodb_spin_wait_delay = 30
innodb_sync_spin_loops = 100
innodb_flush_method = O_DIRECT
innodb_file_per_table = 1
innodb_file_format = Barracuda
innodb_stats_on_metadata = 0 # disable innodb statistic when statistics sql was running
innodb_stats_sample_pages = 8
innodb_max_dirty_pages_pct = 75
innodb_old_blocks_pct = 37
innodb_old_blocks_time = 1000
innodb_open_files = 3000
innodb_read_io_threads = 8
innodb_write_io_threads = 4
innodb_io_capacity = 1000
skip-symbolic-links
default-storage-engine = innodb
# common business settings MySQL node
back_log = 1024
max_connections = 5000 # should be easy job in a big server
max_connect_errors = 100000
max_heap_table_size = 128M
open_files_limit = 65535
thread_cache_size = 128
transaction_isolation = REPEATABLE-READ
table_open_cache = 1024 # table_cache is deprecated in 5.1.3
tmp_table_size = 32M
lower_case_table_names = 1
event_scheduler = 1
log_bin_trust_function_creators = 1
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 1M
join_buffer_size = 1M
net_buffer_length = 16K
thread_stack = 256K
myisam_sort_buffer_size = 16M # myisam sort buffer size
myisam_repair_threads = 1 # myisam auto repair
key_buffer_size = 128M
query_cache_type = 1 # enable use of the query cache altogether
query_cache_size = 0 # disable query cache
tmpdir = /dev/shm
skip-name-resolve
skip-slave-start
character-set-server = utf8 # default-character-set is deprecated in 5.0
collation-server = utf8_general_ci
log_output = FILE
general_log = OFF
slow_query_log = 1 # ON is not recognized in 5.1.46
long_query_time = 1 # in seconds, determine slow query
general_log_file = query.log # log is deprecated as of 5.1.29
slow_query_log_file = slow-query.log # log_slow_queries and log_queries_not_using_index are deprecated as of 5.1.29
slave_skip_errors = 1062 # skip primary duplicate error
log-bin = mysql-bin.log
sync_binlog = 1 # BBU-backed RAID or flash
binlog_format = MIXED # for replication
max_allowed_packet = 1024M # same to master
部署安装
如果没有特殊的需求, 推荐大家下载官方的二进制包进行安装, 可以参考 ansible-role-percona 通过 ansible 进行安装.
高可用
高可用部分为可选项, 不同的基础架构可能需要不同的设置. 在物理机环境中, 我们一般使用 MHA + vip 的方式实现主从切换. 在云环境中由于不支持 vip, 可能需要引入双主或者 LB 等功能实现高可用. 如果预算充足, 也可以考虑 MySQL 的 GROUP Replication.
更多见:
mha4mysql-manager
group-replication
熟悉备份与监控的方式
备份
熟悉以下几种备份方式, 以及不同备份的优缺点, 另外备份完成后需要做完整性检测, mysqldump 及 xtrabackup 备份完成后一般都有确认信息, 是否定期执行恢复测试可按自身需求测试:
mydumper # 可选
mysqldump
xtrabackup
更多见:
监控
粒度越小的监控越能反应系统真实的使用情况, 告警也会更准确, 目前主要是下面两类监控,
zabbix
grafana + prometheus 或 influxdb # 更细粒度, 更方便故障排错
监控的报警则主要包含以下维度:
1. qps 过高(自定义);
2. 当前连接数过多(比如占 max connection 的一定比例);
3. 同时运行的线程过多(超过 cpu 核数);
4. 死锁及长时间运行的 sql 语句;
5. 慢查询监控(如果需要报警, 要提前做好聚合);
更多见:
zabbix-mysql
grafana-dashboard
系统方面的知识
硬件方面
硬件方面主要是熟悉 RAID 卡对系统的影响, 带缓存与不带缓存, RAID 级别以及 writethrough 和 writeback 模式对 io 性能的影响.
更多见: raid 控制器对系统的影响
系统调用及排错优化
需要了解 mem, io 方面的系统调用, 区分同步 io, 异步 io 对系统的性能影响. 了解常规的系统排错工具, 包括 iotop, perf, strace, sysdig 等工具.
更多见:
跟踪系统命令执行
这里为可选, 我们一般使用 snoopy 记录线上主机的所有命令行为, 可以方便我们的事后排错与跟踪分析, 即便机器被黑, 也可以概看出被黑的大致操作步骤.
更多见:
性能相关
性能调优的范围比较广泛, 除了常规的系统参数及硬件调整, 更多的是开发人员对表结构的修改设计, 数据库方面则主要注意 innodb 相关的设置即可. 日常工作中大致需要注意以下几点:
1. 硬件是否正常, 尤其磁盘和 RAID 卡(以及充放电)对数据库的 io 影响很大;
2. 修改表是否有合适的索引;
3. 开发人员是否过度提交(频繁的 select, update, insert 等), 程序是否可以避免过度提交, 引入 cache 等功能;
4. 部分大表是否可以归档清理;
5. 非及时的请求是否可以引入消息队列延后处理;
6. 一定要多关注慢查询, 阈值设为 1s 记录所有的慢查询;
7. 如果有条件, 最好能在测试环境做简单的功能压测;
定期巡检
如果监控和备份比较完备, 不用太过频繁的对系统服务定期巡检, 绝大多数情况下, 能及时关注 cpu 的使用以及出现慢查询即可. 其它方面的账户安全, 数据大小, 系统状态等相关的检查建议每周做一次. 表数据碎片的整理要仔细确认好, 避免表锁影响业务. 线上建议通过 pt-online-schema-change 工具操作.
管理与开发规范
更多见:
MySQL 安装配置规范
MySQL 管理事项规范
MySQL 开发规范
其它
可以了解以下相关的数据库知识:
mysql-tokudb: 提供高压缩比特性, 可以用来存储日志相关的表;
msyqldiff: 监控 MySQL 的表结构及权限的修改;
sys-toolkit: 我的工具集, 包含很多系统和数据库相关的小工具;
mysqltuner: 试试 MySQL 的性能检测工具;
percona-blog: percona 官方博客, 很多数据库问题可以在这里找到解决方法;
elk-mysql-slowlog: 可以试着收集慢查询进行集中处理, 最好也能支持聚合功能;
高性能 MySQL: 广度与深度俱佳的一本 MySQL 书籍;