TokuDB 修改分区表耗时长问题处理
问题说明
在之前的文章[TokuDB 使用简单说明]/tokudb-%E7%89%B9%E6%80%A7%E6%A6%82%E8%A7%88/)中简单介绍了如何使用 TokuDB, 其固有的特性很适合存储日志类的需求, 不过近期在修改 TokuDB 分区表的时候出现操作时间较长的提示, 业务端也同时出现响应时间较长的请求. 如下所示:
# bash text_data_partition.sh 127.0.0.1 3311 text_base text_data
2018_12_05_14_55_39 [info] alter maxvalue of the partitions
2018_12_05_14_55_39 [info] reorganize p20181217 partition
2018_12_05_14_55_44 [info] reorganize p20181217 partition ok
我们按天对 text_data 表进行分区, p20181217 分区为小于 MAXVALUE 的空表, 在增加 p20181218 分区的时候耗时较长, 上述的操作耗时 5s, 查看各子表信息, 所有子分区文件的时间戳都有改变, 不过我们只操作了 p20181217 分区, 理论上来讲应该只有 p20181217 和 p20181218 两个分区的文件属性会改变, 这里所有的分区文件都改变可能意味着修改操作使得 Tokudb 对所有分区进行了一些操作.
# ls -hlt data/tokudb_data/
...
-rw-rw---- 1 mysql mysql 96M Dec 5 14:55 _text_base_text_data_P_p20181203_TMP_key_idx_cretime_198b5d7cf_5_1d.tokudb
-rw-rw---- 1 mysql mysql 96M Dec 5 14:55 _text_base_text_data_P_p20181203_TMP_key_idx_app_group_198b5d7cf_4_1d.tokudb
-rw-rw---- 1 mysql mysql 432M Dec 5 14:55 _text_base_text_data_P_p20181203_TMP_key_unq_taskid_ctime_198b5d7cf_3_1d.tokudb
-rw-rw---- 1 mysql mysql 96M Dec 5 14:55 _text_base_text_data_P_p20181202_TMP_key_idx_app_data_196831bb2_6_1d.tokudb
-rw-rw---- 1 mysql mysql 96M Dec 5 14:55 _text_base_text_data_P_p20181202_TMP_key_idx_updatetime_196831bb2_7_1d.tokudb
...
另外数据库的 binlog 信息则显示 exec_time 为 5, 即 binlog 写入 sql 的时间为 5s, 这个时间算是很长了, 正常情况下空子表的更新都不会这么久:
# at 1001055299
#181205 14:55:40 server id 9309423 end_log_pos 1001055595 CRC32 0xa1aace7a Query thread_id=44673073 exec_time=5 error_code=0
SET TIMESTAMP=1543992940/*!*/;
SET @@session.sql_mode=1073741824/*!*/;
alter table text_data reorganize partition p20181217 into (
partition p20181217 values less than (63712310400),
partition p20181218 values less than MAXVALUE)
分析说明
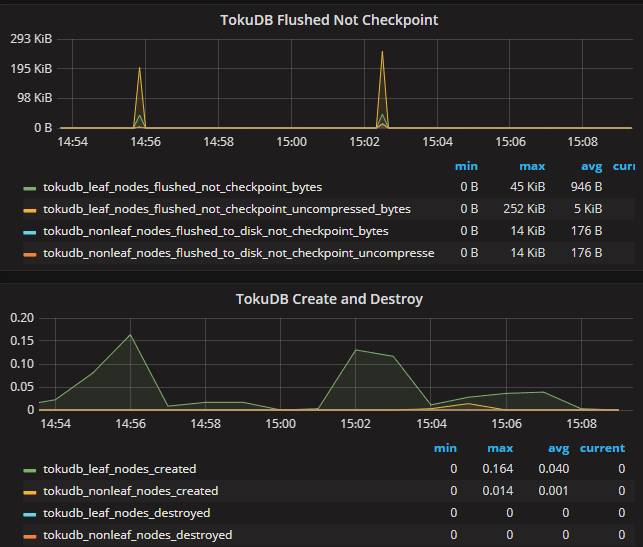
从 TokuDB 的监控图来看, 每次操作表分区, TokuDB 的 checkpoint 刷新, 叶子节点与非叶子节点的创建都会有很明显的波动:
我们在测试环境中复现该问题, 插入几百万数据后再查看语句的 profile 信息:
mysql root@[localhost:s3326 percona] > set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql root@[localhost:s3326 percona] > alter table text_data reorganize partition p20181224 into (partition p20181224 values less than (63712915200), partition p20181225 values less than MAXVALUE);
Query OK, 0 rows affected (6.76 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql root@[localhost:s3326 percona] > show profile for query 1;
+------------------------------+----------+
| Status | Duration |
+------------------------------+----------+
| starting | 0.001013 |
| checking permissions | 0.000060 |
| checking permissions | 0.000047 |
| init | 0.000043 |
| Opening tables | 0.000623 |
| setup | 0.033505 |
| System lock | 0.102880 |
| System lock | 6.617121 |
| Waiting for query cache lock | 0.000034 |
| end | 0.000043 |
| query end | 0.001213 |
| closing tables | 0.000145 |
| freeing items | 0.000129 |
| cleaning up | 0.000151 |
+------------------------------+----------+
14 rows in set, 1 warning (0.01 sec)
可以看到第 2 个 System lock 步骤耗时很长, 使用相应数据库的 debug 版本(这里为 percona5.6.38-debug 版本)查看 trace 信息, 大致如下:
T@561 : | | | | | | | | THD::enter_stage: /home/mysql/percona-server-5.6.38-83.0/sql/lock.cc:306
T@561 : | | | | | | | | >PROFILING::status_change
......
T@561 : | | | | | | | | info: thd->proc_info System lock
T@561 : | | | | | | | | >lock_external
T@561 : | | | | | | | | | info: count 1
T@561 : | | | | | | | | | >handler::ha_external_lock
T@561 : | | | | | | | | | | >ha_partition::external_lock
T@561 : | | | | | | | | | | | info: external_lock(thd, 0) part 0
T@561 : | | | | | | | | | | | >handler::ha_external_lock
T@561 : | | | | | | | | | | | | >external_lock
T@561 : | | | | | | | | | | | | | >my_malloc
T@561 : | | | | | | | | | | | | | | my: size: 96 my_flags: 32
T@561 : | | | | | | | | | | | | | | exit: ptr: 0x7f267e83b200
T@561 : | | | | | | | | | | | | | <my_malloc 66
... -----------------------------
T@561 : | | | | | | | | | | | <handler::ha_external_lock 7872 +
T@561 : | | | | | | | | | | | info: external_lock part 0 lock 0 |
T@561 : | | | | | | | | | | | info: external_lock(thd, 0) part 1 出现次数等于子表数量
T@561 : | | | | | | | | | | | >handler::ha_external_lock
T@561 : | | | | | | | | | | | | >external_lock |
T@561 : | | | | | | | | | | | | <external_lock 6507 +
... -----------------------------
T@561 : | | | | | | <lock_tables 6270
T@561 : | | | | | | >THD::decide_logging_format
T@561 : | | | | | | | info: query: alter table text_data reorganize partition p20181224 into (partition p20181224 values less than (63712915200), partition p20181225
values less than MAXVALUE)
T@561 : | | | | | | | info: variables.binlog_format: 0
...
T@561 : | | | | | | | | | <get_free_ddl_log_entry 1379
T@561 : | | | | | | | | | ddl_log: write type d next 2 name './percona/text_data#P#p20181224#TMP#' from_name '' handler 'TokuDB' tmp_name ''
...
T@561 : | | | | | | | | | <get_free_ddl_log_entry 1379
T@561 : | | | | | | | | | ddl_log: write type d next 6 name './percona/text_data#P#p20181225#TMP#' from_name '' handler 'TokuDB' tmp_name ''
...
T@561 : | | | | | | | | | <create 7422
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181224#TMP# created
...
T@561 : | | | | | | | | | <handler::ha_open 2801
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181224#TMP# opened
T@561 : | | | | | | | | | <handler::ha_external_lock 7872
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181224#TMP# external locked
...
T@561 : | | | | | | | | <tablename_to_filename 523
T@561 : | | | | | | | | info: Add partition ./percona/text_data#P#p20181225#TMP#
...
T@561 : | | | | | | | | | <create 7422
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181225#TMP# created
...
T@561 : | | | | | | | | | <handler::ha_open 2801
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181225#TMP# opened
T@561 : | | | | | | | | | <handler::ha_external_lock 7872
T@561 : | | | | | | | | | info: partition ./percona/text_data#P#p20181225#TMP# external locked
...
T@561 : | | | | | | | | | >MYSQL_BIN_LOG::commit
...
T@561 : | | | | | | >wait_while_table_is_used
T@561 : | | | | | | | enter: table: 'text_data' share: 0x7f261f79e410 db_stat: 39 version: 1
...
T@561 : | | | | | | | >intern_close_table
T@561 : | | | | | | | | tcache: table: 'percona'.'text_data' 0x7f261f66d200
T@561 : | | | | | | | | >free_io_cache
...
T@561 : | | | | | | | >intern_close_table
T@561 : | | | | | | | | tcache: table: 'percona'.'text_data' 0x7f261f66d200
T@561 : | | | | | | | | >free_io_cache
T@561 : | | | | | | | | <free_io_cache 834
T@561 : | | | | | | | | >closefrm
T@561 : | | | | | | | | | enter: table: 0x7f261f66d200
...
T@561 : | | | | | | | | >close
T@561 : | | | | | | | | | >__close
T@561 : | | | | | | | | | | >my_free
T@561 : | | | | | | | | | | | my: ptr: 0x7f261f79ec00
T@561 : | | | | | | | | | | <my_free 141
...
T@561 : | | | | | | >alter_close_table
T@561 : | | | | | | | >get_lock_data
...
T@561 : | | | | | | | | >ha_partition::store_lock
T@561 : | | | | | | | | | info: store lock 0 iteration
T@561 : | | | | | | | | | >store_lock
T@561 : | | | | | | | | | <store_lock 6677
...
T@561 : | | | | | | | | | | >ha_partition::destroy_record_priority_queue
T@561 : | | | | | | | | | | <ha_partition::destroy_record_priority_queue 5171
...
T@561 : | | | | | | | | | <ha_partition::~ha_partition() 443
T@561 : | | | | | | | | | >free_items
...
T@561 : | | | | | | >THD::binlog_query
T@561 : | | | | | | | enter: qtype: STMT query: 'alter table text_data reorganize partition p20181224 into (partition p20181224 values less than (63712915200), parti
tion p20181225 values less than MAXVALUE)'
...
T@561 : | | | | | | | | <tablename_to_filename 523
T@561 : | | | | | | | | info: Rename partition from ./percona/text_data#P#p20181224#TMP# to ./percona/text_data#P#p20181224
...
T@561 : | | | | | | | | <tablename_to_filename 523
T@561 : | | | | | | | | info: Rename partition from ./percona/text_data#P#p20181225#TMP# to ./percona/text_data#P#p20181225
...
T@561 : | | | | | | | <release_part_info_log_entries 6025
T@561 : | | | | | | <write_log_completed 6624
...
T@561 : | | | | | | | | | >ha_partition::~ha_partition()
T@561 : | | | | | | | | | | >~ha_tokudb
T@561 : | | | | | | | | | | <~ha_tokudb 1260
...
mysqld debug 功能没有时间戳选项, 看起来会比较混乱, 只能靠层级信息大致区分, 不过我们可以看到整个修改过程大致为 获取lock -> 创建相关的 tmp 子表 -> binlog 记录 -> 交换临时子表为最终的子表, 整个过程在 system lock,intern_close_table, store_lock, ~ha_partition 的步骤中都进行了很多的循环操作, 循环次数等同子表的数量; ~ha_tokudb 函数则对每个子表文件(包含 key 文件及数据文件) 进行了清理释放操作:
# ha_tokudb.cc
---------------------------------------------------------------------
ha_tokudb::~ha_tokudb() {
TOKUDB_HANDLER_DBUG_ENTER("");
for (uint32_t i = 0; i < sizeof(mult_key_dbt_array)/sizeof(mult_key_dbt_array[0]); i++) {
toku_dbt_array_destroy(&mult_key_dbt_array[i]);
}
for (uint32_t i = 0; i < sizeof(mult_rec_dbt_array)/sizeof(mult_rec_dbt_array[0]); i++) {
toku_dbt_array_destroy(&mult_rec_dbt_array[i]);
}
TOKUDB_HANDLER_DBUG_VOID_RETURN;
}
# PerconaFT/util/dbt.cc
---------------------------------------------------------------------
void toku_dbt_array_destroy_shallow(DBT_ARRAY *dbts) {
toku_free(dbts->dbts);
ZERO_STRUCT(*dbts);
}
void toku_dbt_array_destroy(DBT_ARRAY *dbts) {
for (uint32_t i = 0; i < dbts->capacity; i++) {
toku_destroy_dbt(&dbts->dbts[i]);
}
toku_dbt_array_destroy_shallow(dbts);
}
void toku_destroy_dbt(DBT *dbt) {
switch (dbt->flags) {
case DB_DBT_MALLOC:
case DB_DBT_REALLOC:
toku_free(dbt->data);
toku_init_dbt(dbt);
break;
}
}
参考文章 aliyun-280964 可以看到 TokuDB 采用了比较激进的缓存策略, 尽量把数据保留再内存中, 这就意味着更新越多, 内存中的脏数据也就越多, 数据刷新到磁盘的时间也会越多, 这也是上述监控图像中 checkpoint 等数据明显波动的原因. 从这方面来看修改分区的操作触发了 TokuDB 底层 Fractal Tree 结构中脏数据等状态的刷新, 对 text_data 表而言, 大约有 193*7 = 1351 (包含 key 文件, 数据文件) 个子表文件需要处理, 数量过多可能是引起操作较慢的原因. 基于这点清理一个月之前的所有表分区, 仅保留最近一月的数据:
mysql root@[localhost:s3311 text_base] > alter table text_data drop partition p20180522;
Query OK, 0 rows affected (0.99 sec)
Records: 0 Duplicates: 0 Warnings: 0
....
mysql root@[localhost:s3311 text_base] > alter table text_data drop partition p20180802;
Query OK, 0 rows affected (0.80 sec)
Records: 0 Duplicates: 0 Warnings: 0
....
mysql root@[localhost:s3311 text_base] > alter table text_data drop partition p20181104;
Query OK, 0 rows affected (0.34 sec)
Records: 0 Duplicates: 0 Warnings: 0
从上述信息可以看到, 随着分区表的清理, drop 的消耗时间也越来越短. 清理完成后仅剩 30 * 7 = 210 个字表文件, 之后再手动执行脚本, 整体时间已经控制在 1s 内, 从 [snoopy]/how-does-snoopy-log-every-executed-command/) 的时间戳来看, 修改子表操作一共消耗 847 - 475 = 372ms:
# bash text_data_partition.sh 127.0.0.1 3311 text_base text_data
2018_12_05_16_33_10 [info] alter maxvalue of the partitions
2018_12_05_16_33_10 [info] reorganize p20181219 partition
2018_12_05_16_33_10 [info] reorganize p20181219 partition ok
# less /var/log/secure
...
Dec 5 16:33:10 apphost1 snoopy[3771]: [time_ms:475 login:cz uid:0 pid:3771 sid:1234 ]: mysql -h 127.0.0.1 -P 3311 -D text_base ......
Dec 5 16:33:10 apphost1 snoopy[3773]: [time_ms:847 login:cz uid:0 pid:3773 sid:1234]: date +%F-%T
...
总结
实际上我们并没有搞清楚修改空的 TokuDB 子表为什么会引起刷新所有的子表数据, percona 官方文档中也没有看到相关控制选项的说明, 可能是为了数据的一致性, 毕竟 tokudb 是通过 promotion 方式来缓存脏数据. InnoDB 中还未碰到过类似的情况. 另外如果不能清理线上子表, 可以考虑在低峰时间段一次创建多个新的子表减少操作的频率.
参考:
aliyun-280964
tokudb-table-optimization-improvements
improve-tokudbperconaft-fragmented-data-file-performance