在云中使用 proxy protocol
背景说明
在 http/https 的协议中, 我们可以通过 X-Forwarded-For 从 Header 信息中获取到离服务端最近的 client 端的 IP 地址, 如果请求经过了多级代理且每级代理都开启此特性, 就可以获得真实有效的用户 IP. 不过这种特性是基于应用层实现, 并不适用于传输层. 在基于 tcp 层的转发场景中, 获取真实有效的用户 IP 显得更为重要.
Linux 内核从 2.2 版本开始支持透明代理(tproxy), 可以在传输层转发的情况下获取用户的 IP, 早期的版本需要在内核编译的时候开启此特性, 从 4.18 版本开始 tproxy 特性可以在 nf_tables 中直接使用. 不过遗憾的是在云环境中, 我们无法在使用了 load balance 的场景中使用此特性.
参考 cloudflare 提供的文章 routing-to-preserve client IP, 为我们提供了几个可选的思路:
忽略用户 IP
这种方式只针对不需要获取用户 IP 的业务, 比如只关注服务是否正常的业务.
非标准的 TCP header
这种方式基于修改 TCP 的包头实现, 在 TCP 的连接建立(SYN)阶段就将用户的 IP 加到 TCP 头部的可选字段中, 这种方式对数据报文的开销较大, IPV6 则更为明显. 即便最近几年有 RFC 7974 协议的支持, 目前也没有多少软件支持此特性. 另外实现这种方式可能需要在系统调用的层面进行修改, 所以应用层很难支持实现此方式. 国内的几家云厂商提供的类似 TOA 即是基于此机制以内核模块的方式获取用户 ip, 详见: toa_get_client-ip, aliyun-toa.
使用 PROXY protocol
proxy protocol 最早由 HAproxy 发明实现. 是一种类似 X-Forwarded-For 的基于应用层实现的方式. 由于是基于应用层, 所以需要客户端和服务器端同时支持此协议.
在云环境中, 大多数云厂商的 load balance 支持此方式, 如下所示:
flowchart LR
A[client] ---> |1| B[cloud LB]
B ---> |2| C[haproxy/nginx...]
C ---> |3| D[app server]
就上图来看, 整个 proxy protocol 在第 2 步实现, 这里的 cloud LB 相当于客户端, haproxy/nginx.. 等相当于服务端. 如果服务端软件支持发送 proxy protocol 功能, 也可以将真实的用户 IP 发送到第 3 步的 app server 中. 当然如果 app server 支持此方式, 可以直接去掉上述的 haproxy/nginx... 部分直接和 load balance 通信. 目前已知的支持 proxy protocol 特性的主要包含以下软件:
Elastic Load Balancing(AWS's load-balancer)
GCP LB(Google Cloud load-balancer)
haproxy
nginx
Percona MySQL Server
postfix
varnish
apache-httpd
更多列表可参考 proxy-protocol ready softwares, 其它软件可详细查看各软件文档的手册说明.
PROXY protocol 如何工作
proxy protocol 支持 v1 和 v2 两个版本. v1 版本以明文的字符串发送数据, v2 版本以二进制格式发送. 简单而言, proxy protocol 实现主要是在建立 TCP 连接后, 在发送应用数据之前先将用户的 IP 信息发送到服务端. 我们可以简单理解为 TCP 三次握手完成后由 proxy protocol 的客户端立即将用户的 IP 信息发送过来. 以 v1 版本的格式为例, 如下所示:
PROXY TCP4 139.162.138.99 34.96.112.131 55372 5222\r\n
对比上述的图来看:
139.162.138.99 -> client ip
34.96.112.131 -> cloud LB ip
55372 -> client source port
5222 -> cloud LB dest port
haproxy/nginx.. 等 proxy protocol 服务端接收到此消息后会将自身连接中的 client ip 修改为收到的 client ip, 以 haproxy 的日志为例, 基于日志和ip等策略的封禁会以修改后的 client ip 为准, 真实的 tcp 交互还是和上述的 cloud LB, app server 进行交互. 如下所示为简单的日志信息:
08/Jan/2020:04:15:00 +0000 139.162.108.99:55372 10.140.0.25:6379 0 redis7379 redis7379 10.140.15.192:10722
通过 tcpdump 抓包来看则更为清晰明了, 如下所示, 在 haproxy 机器中抓包后, 可以看到 tcp 三次握手完成后就立马收到 proxy protocol 信息, 下图中的红色圈里即为数据信息, 该信息由 cloud LB 发送, 之后则为真实的应用层交互(绿色圈):
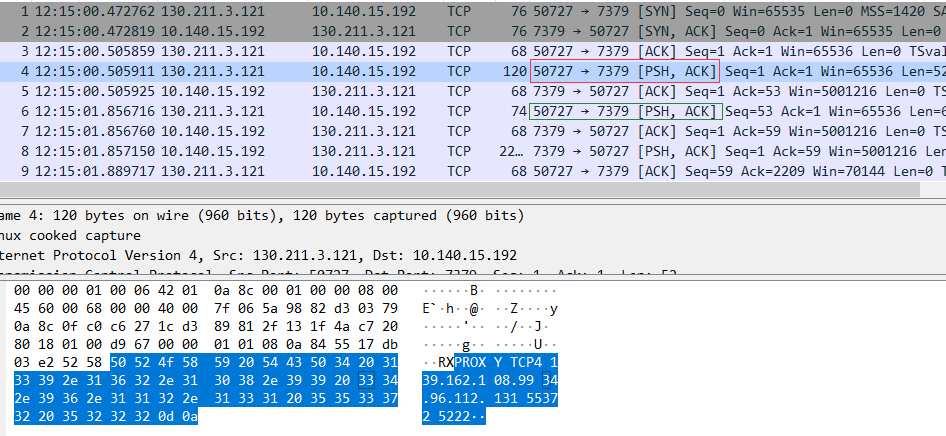
从这方面来看, 不难想象为什么说需要客户端和服务端都要支持 proxy protocol 才可以实现此方式. 另外服务端在处理协议数据的时候应该严格按照协议的规定, 只处理业务数据最开始的部分, 这样才能避免伪造数据的风险, 以如下为例, 通过 nc 发送假的数据:
# echo -en "PROXY TCP4 1.2.3.4 1.2.3.4 11 11\r\nHello World" | nc -v 34.96.112.131 5222
Connection to 34.96.112.131 5222 port [tcp/xmpp-client] succeeded!
-ERR unknown command 'PROXY' # 这里的报错是因为收到假的数据且不支持处理
cloud lb 支持 proxy protocol 协议, 在 haproxy 中抓包可以看到有两串类似的 PROXY TCP4 数据, 仅挨着三次握手后的第一条即为真实的信息(黄色圈), 后续的为伪造的信息(绿色圈):
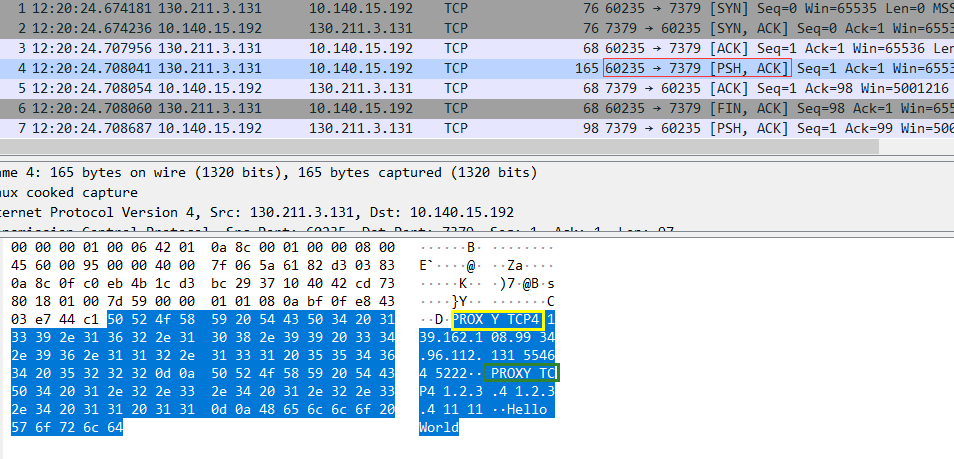
在云中使用 PROXY protocol
从上述的说明来看, 在云环境中通过传输层获取 client ip 大概有以下几种方式:
第一种:
flowchart LR
A[client] ---> |1| B[app server]
第二种:
flowchart LR
A[client] ---> |1| B[cloud LB]
B ---> |2| C[app server]
第三种:
flowchart LR
A[client] ---> |1| B[cloud LB]
B ---> |2| C[haproxy/nginx...]
C ---> |3| D[app server]
备注: 这里我们假定
app server为非http/https服务.
第一种为很常见的直连方式, 不需要依赖其它云服务, 但是在受到攻击(比如 ddos) 的时候, 可能就需要依赖云厂商的服务进行攻击防护.
使用了云服务后, 就可以通过 2, 3 两种方式, 这里我们以 cloud LB 为例说明, app server 想要获取到 client 的 IP, 就需要 cloud LB 支持 proxy protocol 特性, 在开启特性的情况下, cloud LB 就相当于 proxy protocol 的客户端负责发送真实的 client ip.
在第 2 种方式中, 由于没有中间工具, 就需要 app server 本身支持 proxy protocol 作为接收端. 因为是解析应用层的数据, 所以支持此特性可能就意味着 app server 性能的损耗, 现实中很少有业务直接支持 proxy protocol.
第 3 种方式则在 cloud LB 和 app server 之间引入 haproxy 等支持 proxy procotol 的代理工具. 这里的 haproxy 则作为 proxy procotol 的服务端接收数据, 并得到真实的用户 ip, 我们可以根据用户 ip 做很多策略方面的限制. haproxy 转发到后端 app server 仅为正常的业务数据. 如果 app server 也支持 proxy protocol 并且需要获取真实的 ip, 可以配置 haproxy 将收到的 proxy protocol 数据转发到后端的 app server. 如下所示为简单的 haproxy 配置示例:
global
log 127.0.0.1:514 local2
maxconn 64000
nbproc 1
nbthread 4
cpu-map auto:1/1-4 0-3
chroot /var/empty
stats socket /var/run/haproxy-admin.sock mode 660 level admin
stats timeout 5s
user haproxy
group haproxy
daemon
defaults
mode tcp
log global
log-format %T\ %ci:%cp\ %si:%sp\ %ST\ %b\ %f\ %bi:%bp
maxconn 51200
retries 2
timeout connect 8s
timeout server 30m
timeout client 30m
timeout client-fin 30s
timeout server-fin 30s
backlog 10240
listen tredis7379
mode tcp
bind *:7379 accept-proxy # 接受云厂商发来的 proxy protocol 数据, haproxy 会将数据里的 ip 作为用户 ip;
server redis1 10.0.21.5:6379 # send-proxy # 指定 send-proxy 或 send-proxy-v2 可以将收到的 proxy protocol 数据转给后端程序;
# tcp 连接限制
stick-table type ip size 200k expire 1m store conn_rate(3s),conn_cnt
acl tcp_conn_above src_conn_rate gt 5
acl tcp_total_above src_conn_cnt ge 30
tcp-request connection track-sc1 src
tcp-request content accept if tcp_conn_above tcp_total_above
# 创建封禁 ip 的规则, 192.168.0.1 可以是虚假的 ip, 可通过 api 接口操作 socket 动态增加需要封禁的 IP.
acl rejectrule src 192.168.0.1
tcp-request content reject if rejectrule
日志格式
日志格式可以参考 haproxy-log-format, 上述的配置中我们没有开启 tcplog 选项, 日志中包含连接状态(比如持续时间等)的时候, 仅在连接关闭的时候才会输出日志, 这种情况下我们无法及时获取 ip 信息做更细致的策略封禁. 上述的配置中仅包含通用的连接信息, 在 tcp 建立的时候就能记录到日志, 方便我们及时处理.
tcp 连接限制
上述的配置中我们也对 tcp 的连接做了两方面的限制, 同时满足下面两个条件则 haproxy 拒绝 client ip 建立新的 tcp 连接:
1. 单个 ip 每 3 秒新建 tcp 连接数超过 5;
2. 单个 ip 总的 tcp 连接数超过 30;
在上述的配置中, conn_rate(3s) 取 3s 作为新建连接平均值的时间跨度, 对应 src_conn_rate gt 5 来看就是 3 秒内的新建连接数不能超过 5. 另外需要注意的是, haproxy 在进行策略限制的时候是先通过 stick-table 进行计数, 满足条件的时候直接应用规则进行拒绝, 而不是我们传统认为的先允许阈值之下的进行连接, 超过阈值之后再应用规则拒绝. 所以从这方面来看, 如果 3s 内的新建连接数超过 5, 那么这 3 秒内就不会有新的连接创建成功.
更多策略规则可参考 haproxy-configuration 的 stick-table 部分.
acl 动态封禁
上述的 acl rejectrule 可以用来进行动态的 ip 封禁. 对于 haproxy 而言, 其提供了 haproxy-socket 方式方便我们对 frontend, backend, acl 等进行动态的修改. 如下所示:
# echo "show acl #1" | socat stdio /var/run/haproxy-lb.sock
0x562faf390f00 192.168.0.1
# echo "add acl #1 139.162.108.99" | socat stdio /var/run/haproxy-lb.sock
# echo "show acl #1" | socat stdio /var/run/haproxy-lb.sock
0x562faf390f00 192.168.0.1
0x562faf5b9fd0 139.162.108.99
在 139.162.108.99 主机中即可发现连接被拒绝:
# telnet 34.96.112.131 5222
Trying 34.96.112.131...
Connected to 34.96.112.131.
Escape character is '^]'.
Connection closed by foreign host.
我们也可以基于 socket 的动态特性定制维护工具, 更多操作示例可以参考工具 haproxytool.
reject 封禁问题
在上述的连接限制和动态封禁的规则中, 我们都使用了 tcp-request content reject ... 规则, 为什么没有使用 tcp-reques connection reject ... 的原因在于我们使用的 proxy protocol 是基于应用层实现, haproxy 必须要解析应用层的数据才能够进行后续的处理. 所以这里的 content 是必须的条件, 如果使用了 connection 那么限制的就不是 client ip, 而是 cloud LB 的 ip 信息.
另外, 我们在进行动态封禁的时候, 最好忽略掉 cloud LB 的地址以免引起误封. 具体的 ip 列表可以参考各云厂商的手册文档.
多进程和多线程
nbproc 和 nbthread 是两种可以使用多核 cpu 的方式, nbproc 比较传统是以多进程的方式服务, 且调试起来比较麻烦. nbthread 为 1.8 版本新增的多线程功能, 在 1.8.x 的早期还只是实验性质, 在最新的 1.8.23 版本中, 多线程功能已经稳定可用, 如下所示:
nbproc <number>
Creates <number> processes when going daemon. This requires the "daemon"
mode. By default, only one process is created, which is the recommended mode
of operation. For systems limited to small sets of file descriptors per
process, it may be needed to fork multiple daemons. USING MULTIPLE PROCESSES
IS HARDER TO DEBUG AND IS REALLY DISCOURAGED. See also "daemon" and
"nbthread".
nbthread <number>
This setting is only available when support for threads was built in. It
creates <number> threads for each created processes. It means if HAProxy is
started in foreground, it only creates <number> threads for the first
process. See also "nbproc".
不过两者也存在一些差别, 多进程方式的每个进程都相当于独立的个体, 一些策略和状态的应用则只是针对单个进程而非所有进程, 更详细的可以参考: multi-process and multithreading, 下面仅列出多进程的一些限制:
1. 不同进程之间需要同步 stick-table 等配置;
2. 状态统计, 策略及限制等功能仅针对单进程, 并非全局;
3. 每个进程都会进程监控检测;
4. 任何需要执行运行时 API 的指令都需要发送到每个进程;
从实际的测试来, 如果启用 tcp 等限速策略, 上述的 单个 ip 每 3 秒新建 tcp 连接数超过 5 适用于单个进程, 如果有 3 个进程, 单个 ip 每 3 秒新建的连接数超过 15 才会满足条件. 多线程则没有此类问题, 单个进程中的线程共享状态统计, 策略限制等信息. 如果需要准确的执行策略限制建议开始多线程模式. 上述的配置中:
nbproc 1
nbthread 4
cpu-map auto:1/1-4 0-3
仅开启单个进程, 该进程开启 4 个线程, 每个线程对应使用 cpu0 ~ cpu3.
HAProxy 注意事项
如果以 HAProxy 作为 proxy protocol 的服务端, 需要注意以下一些问题:
参数设置
在使用单进程模式的时候, 需要将单个进程的资源设置的足够大, 如下参数设置仅供参考:
# 内核参数
kernel.pid_max = 102400
kernel.threads-max = 409600
vm.max_map_count = 102400
net.ipv4.ip_local_port_range = 1024 65530
net.ipv4.tcp_max_syn_backlog = 10240
net.core.somaxconn = 8192
net.netfilter.nf_conntrack_max = 2621440
net.core.netdev_max_backlog = 40960
net.ipv4.tcp_tw_reuse = 0
# ulimit 参数
ulimit -n 655350
本地端口耗尽问题
在 client 端(用户 或 cloud LB)连接 haproxy 的时候, 意味着 haproxy 也需要启用一个本地端口来连接后端的 app server, 对 tcp/udp 而言, 由于端口仅占 2 个字节, 所以单 ip 最大可用的本地端口的数量即为 2^16 = 65535, 云环境中单实例一般都不支持设置多 ip, 所以 haproxy -> app server 最多可以建立 65535 个连接, 当然一般连接的数量会比这个理论值少. 如果是短连接业务, 同时能够建立的连接会更少. 在 haproxy 的配置中最好能够让 haproxy -> app server 通过长连接进行保持, 如果无法保持, 端口耗尽的快慢则由具体的请求速度决定.
值得一提的是如果一台机器中监听了很多端口, 则可能出现性能的问题. Linux 内核是通过 LHTABLE 存储的 socket 监听, 如下所示:
/* Yes, really, this is all you need. */
#define INET_LHTABLE_SIZE 32
所以本地监听的端口越多, 通过 LHTABLE 查找的时间越长, 性能的影响就越严重, 更细节的相关测试见 revenge-listening-sockets.
不同版本的特性
如果是带着特定目的而使用 HAProxy, 需要注意不同版本的区别, 目前几个大版本大概有不同的特性, 越新的版本支持的功能越丰富, 大致如下:
haproxy 1.5 - 2010
+ server side Keep-Alive
+ SSL and compression
haproxy 1.6 - 2015
+ server side connection multiplexing
+- dynamic buffer allocation
+- replaced zlib with an in-house, stateless implementation
haproxy 1.7 - 2016
+ runtime API
+ stream processing offload engine
haproxy 1.8 - 2017
+ introduced multithreading
+ New mux layer
haproxy 1.9 - 2018
+ http2(enable gRPC)
+ internal HTTP representation
+ improved scalability multithreading feathre
haproxy 2.0 - 2019
+ process manager
+ k8s ingress controller
+ data plane API
+ Prometheus exporter
+ layer 7 retries
Centos/RedHat 6/7 中目前的 rpm 为 1.5 版本, Ubuntu 18.04 为 1.8 版本. 对于存在动态封禁及修改需求的业务建议使用 1.8 版本. 更多不同版本的特性详见 the history of haproxy.
MMProxy && go-mmproxy
文章 cloudflare-mmproxy 着重介绍了 mmproxy 工具, 如下图所示:
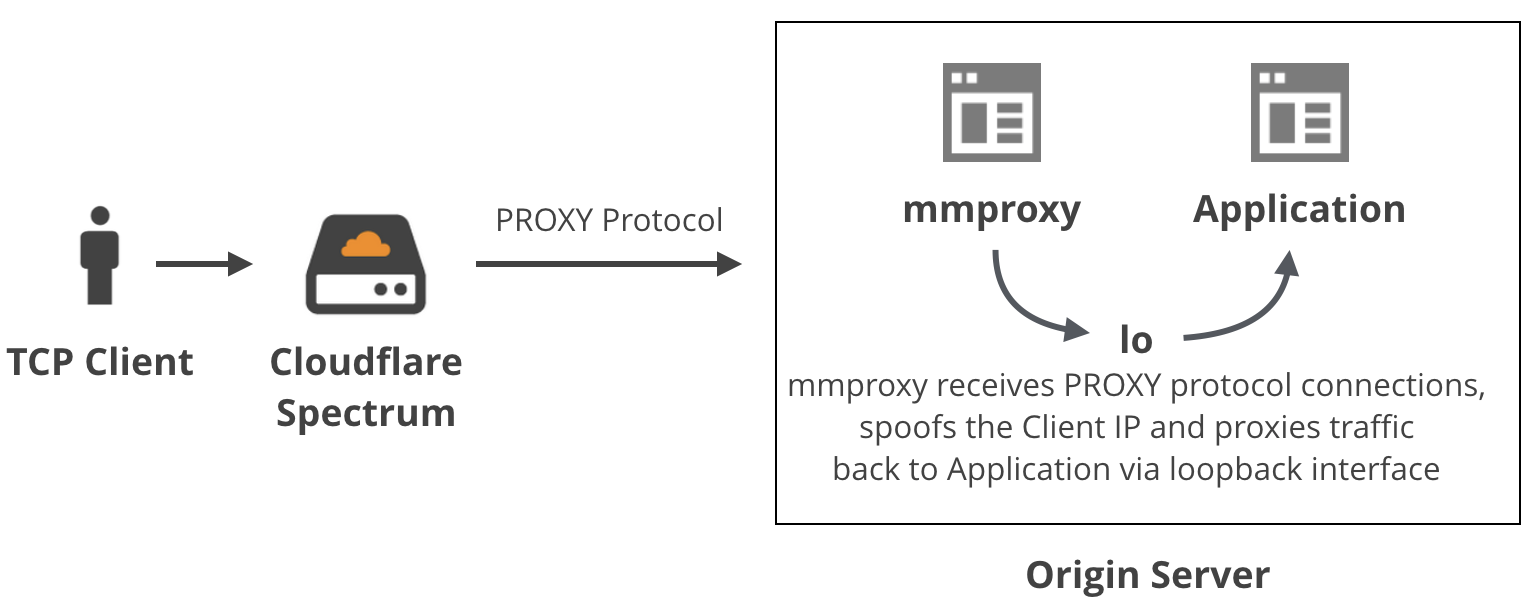
mmproxy 依赖 iptables 的 mangle 链, 本地路由等方式实现此功能, 使用本地 lo 接口处理收到的 proxy protocol 数据以获取 client ip. 这种方式的好处是不需要 haproxy 等中转工具, 效率高. 缺点也很明显, 主要包括以下:
1. 仅适用于 Linux 系统;
2. 必须和 app server 部署到一起;
3. 需要修改 iptable 及本地的路由规则;
4. 需要 root 权限启动;
5. mmproxy 还不够稳定, 只是实验版本;
我们在实际的测试过程中, 也频繁出现内存泄漏的问题, 如下所示:
panic: not enough memory to allocate coroutine stack Bad system call
该错误由 mmproxy 依赖的 go 语言风格的协程并发库 libmill 抛出, 看 github 中的状态, 该工程已经很久未见更新, 此类问题可能不会修复.
另外一个类似的工具为 go-mmproxy, 和 mmproxy 的工作原理相同, 通过 go 语言实现, 从测试的效率来看性能要高很多, 不过使用的人较少, 优缺点同 mmproxy. 由于没有足够的使用案例, 最好在使用前做好充足的测试.
参考
proxy-protocol
use-proxy-protocol-to-better-secure-your-database
the-history-of-haproxy
gcp-set-proxy-protocol
cloudflare-preserving-client-ips-in-sectrum
cloudflare-built-sectrum
haproxy-runtime-api
multi-process and multithreading
haproxytool